我有一個值字典 ( drug) 如下:{0: {0: 100.0, 1: 0.41249706379061035, 2: 5.144449764434768, 3: 31.078456871927678}, 1: {0: 100.0, 1: 0.6688801420346955, 2: 77.32360971119694, 3: 78.15132480853421}, 2: {0: 100.0, 1: 136.01949766418852, 2: 163.4967732211563, 3: 146.7726208999281}}它包含 3 種藥物類型,然后該藥物類型在 4 種不同濃度下的功效。我正在嘗試制作一個簇狀條形圖,將 3 種藥物相互進行比較,如下所示:https://i.stack.imgur.com/wKIRs.png 目前,我的代碼如下:fig, ax = plt.subplots()width = 0.35ind = np.arange(3)for x in range(3): ax.bar(ind + (width * x), drug[x].values(), width, bottom=0)ax.set_title('Drug efficacy')ax.set_xticks(ind + width / 2)ax.set_xticklabels(list(string.ascii_uppercase[0:drugCount]))ax.autoscale_view()plt.show()我已經改編了本指南中的代碼,但遇到了多個問題。我認為主要原因是示例中使用的數據使得一組中的值對應于相同的顏色而不是相同的簇。我如何調整此代碼,以便與其他藥物相比,能夠單獨繪制每種藥物在 4 種不同濃度下的功效?
1 回答
侃侃爾雅
TA貢獻1801條經驗 獲得超16個贊
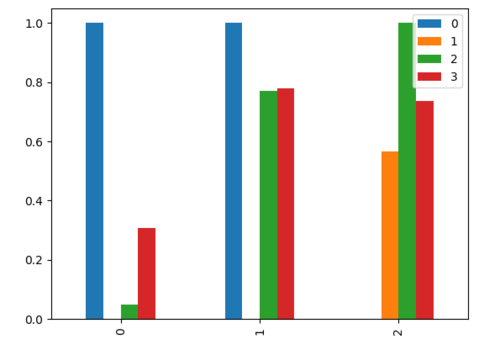
IIUC 您想按列標準化您的值,可以使用以下命令來完成sklearn:
from sklearn import preprocessing
df = pd.DataFrame(drug)
scaler = preprocessing.MinMaxScaler()
df = pd.DataFrame(scaler.fit_transform(df))
df.T.plot(kind="bar")
plt.show()
添加回答
舉報
0/150
提交
取消