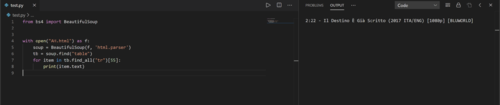
我對 Python 中的 Beautiful Soup 非常熟悉,我一直用來抓取實時網站。現在我正在抓取本地 HTML 文件(鏈接,如果您想測試代碼),唯一的問題是重音字符沒有以正確的方式表示(在抓取實時網站時,我從未發生過這種情況)。這是代碼的簡化版本import requests, urllib.request, time, unicodedata, csvfrom bs4 import BeautifulSoupsoup = BeautifulSoup(open('AH.html'), "html.parser")tables = soup.find_all('table')titles = tables[0].find_all('tr')print(titles[55].text)打印以下輸出2:22 - Il Destino ?? Gi? Scritto (2017 ITA/ENG) [1080p] [BLUWORLD]而正確的輸出應該是2:22 - Il Destino è Già Scritto (2017 ITA/ENG) [1080p] [BLUWORLD]我尋找解決方案,閱讀了許多問題/答案并找到了這個答案,我通過以下方式實現了它import requests, urllib.request, time, unicodedata, csvfrom bs4 import BeautifulSoupimport codecsresponse = open('AH.html')content = response.read()html = codecs.decode(content, 'utf-8')soup = BeautifulSoup(html, "html.parser")但是,它運行時出現以下錯誤Traceback (most recent call last): File "C:\Users\user\AppData\Local\Programs\Python\Python37-32\lib\encodings\utf_8.py", line 16, in decode return codecs.utf_8_decode(input, errors, True)TypeError: a bytes-like object is required, not 'str'The above exception was the direct cause of the following exception:Traceback (most recent call last): File "C:\Users\user\Desktop\score.py", line 8, in <module> html = codecs.decode(content, 'utf-8')TypeError: decoding with 'utf-8' codec failed (TypeError: a bytes-like object is required, not 'str')我想解決這個問題很容易,但是怎么辦呢?
在本地 HTML 文件上使用 Python 中的 Beautiful Soup 時出現錯誤的重音字符
慕桂英4014372
2023-09-18 17:18:04