我想從此頁面抓取比賽結果:https://www.tennisexplorer.com/player/paire-4a33b/從抓取的結果中,我想創建包含以下列的表:tournament、date、match_player_1、match_player_2、round、score 我創建了一個代碼,它有效,但我不知道如何為每個比賽行添加比賽import requestsfrom bs4 import BeautifulSoupu = 'https://www.tennisexplorer.com/player/paire-4a33b/'r = requests.get(u, timeout=120, headers=headers)# print(r.status_code)soup = BeautifulSoup(r.content, 'html.parser')for tr in soup.select('#matches-2020-1-data tr'): match_date = tr.select_one('td:nth-of-type(1)').get_text(strip=True) match_surface = tr.select_one('td:nth-of-type(2)').get_text(strip=True) match = tr.select_one('td:nth-of-type(3)').get_text(strip=True)#...我需要像這樣創建表:tournament date match_player_1 match_player_2 round scoreCincinnati Masters (New York) 22.08. Coric B. Paire B. 1R 6-0, 1-0Ultimate Tennis Showdown 2 01.08. Moutet C. Paire B. NaN 15-0, 15-0, 15-0, 15-0我如何將錦標賽與每場比賽聯系起來
2 回答
30秒到達戰場
TA貢獻1828條經驗 獲得超6個贊
要獲得所需的 DataFrame,您可以這樣做:
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = 'https://www.tennisexplorer.com/player/paire-4a33b/'
soup = BeautifulSoup( requests.get(url).content, 'html.parser' )
all_data = []
for row in soup.select('#matches-2020-1-data tr:not(:has(th))'):
tds = [td.get_text(strip=True, separator=' ') for td in row.select('td')]
all_data.append({
'tournament': row.find_previous('tr', class_='head flags').find('td').get_text(strip=True),
'date': tds[0],
'match_player_1': tds[2].split('-')[0].strip(),
'match_player_2': tds[2].split('-')[-1].strip(),
'round': tds[3],
'score': tds[4]
})
df = pd.DataFrame(all_data)
df.to_csv('data.csv')
保存data.csv(來自 LibreOffice 的屏幕截圖):
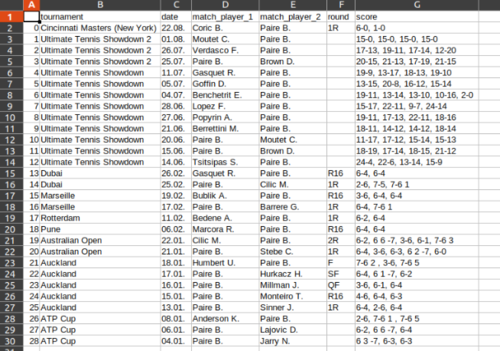
一只甜甜圈
TA貢獻1836條經驗 獲得超5個贊
嘗試一下:
import pandas as pd
url = "https://www.tennisexplorer.com/player/paire-4a33b/"
df = pd.read_html(url)[8]
new_data = {"tournament":[], "date":[], "match_player_1":[], "match_player_2":[],
"round":[], "score":[]}
for index, row in df.iterrows():
try:
date = float(row.iloc[0][:-1])
new_data["tournament"].append(tourn)
new_data["date"].append(row.iloc[0])
new_data["match_player_1"].append(row.iloc[2].split("-")[0])
new_data["match_player_2"].append(row.iloc[2].split("-")[1])
new_data["round"].append(row.iloc[3])
new_data["score"].append(row.iloc[4])
except Exception as e:
tourn = row.iloc[0]
data = pd.DataFrame(new_data)
添加回答
舉報
0/150
提交
取消